上一篇文章我们看到了语音识别的效果图,同时获得了如何在百度申请语音识别的AppID以及APIKey;如果一切没有问题,我们在上篇文章下载Demo示例,并按图组装ReSpeaker 4-Mic麦克风扩展板以及替换已申请的ID和Key后执行可以得到语音识别的初步效果;接下来这篇文章主要讲解一些在开发和实验过程中需要注意的点以及Demo代码的部分含义。
#先看baidu_analysis.py文件,这个文件主要是用来跟百度的语音识别交互的文件;从第一行往下看:
import为引入模块,如果代码执行的时候报 ModuleNotFoundError: No module named 'XXX',说明你的环境缺少这个模块;需要执行安装,以代码中用到的requests模块为例(如果环境是Python3 则pip替换为pip3):
其实requests这个模块在百度的官方demo里面是没有的;这次添加主要是看到官方demo每次都要判断Python版本,请求的过程有点繁琐添加的。
紧接着后面是CUID、RATE等常量的定义;其中CUID官方的解释是“用户的唯一标示,用来区分用户,可以用本机的MAC地址”,实际请求中代码用的是shumeijiang,这个可以自定义就好;其他参数Demo都有中文注释就不再重复;
后面是定义了一个BaiduAnalysis类,不同官方Demo,此处将AppID和ApiKey作为参数传过来,然后定义在调用文件内;方法fetch_token是用来获取token的,含义就是请求前先要做身份验证,这个函数验证后会得到一个短期有效的token;紧接着后面的方法是speech_analysis,这个方法在拿到token后将获得语音文件或者读取的语音流传给百度的Api分析;参数不复杂,不同的地方在于官方的Demo是采用的json格式发送,我们采用的是raw格式发送,两者的效果是一样的;需要注意的是header部分信息,内容类型格式要统一。
接下来是run.py这个文件是程序的入口,Demo要执行起来也需要执行Python run.py;从上往下看可以看到需要用到 pyaudio,它是主要用来做语音捕获,后面定义一些常量定义捕获的参数;pyaudio这部分可以参考网上有很多资料,此处不再详述;接着是GPIO的设置,主要是ReSpeaker 4-Mic所需的,见下图:
再往后是函数listen(),作用是获取捕获的语音流,然后发送给百度api进行翻译识别,其中需要注意的是返回的数据结构如下图(官方示例):
{"corpus_no":"6433214037620997779","err_msg":"success.","err_no":0,"result":["北京科技馆,"],"sn":"371191073711497849365"}
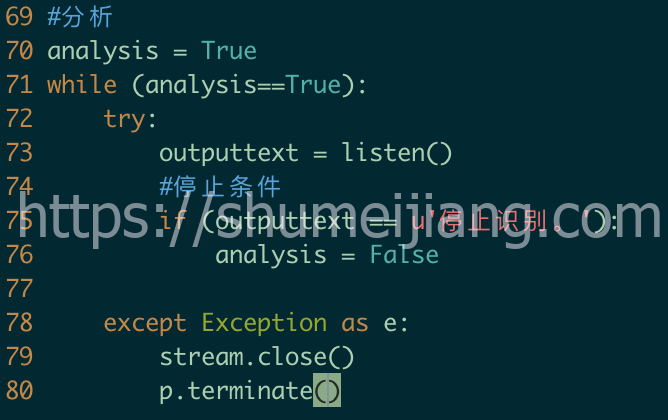
listen函数定义好后,需要调用执行才能获取数据,while (analysis==True):定义了一个可中断的循环策略,当我们语言“停止识别”时,程序匹配然后会自动终止识别,这个终止条件可以自己设定。
 执行策略
执行策略