通过前面两篇树莓派语音识别文章的介绍与学习,我们此时应该已初步可以实现语音的解析和翻译,并在我们的屏幕上打印出来;但是会发现一些问题就是一些解析出来的词容易混淆,如“就酱”和“九江”,“游戏”和“有戏”等等,发言相似的词还是会出现识别的不准确,这个问题可以通过百度的语音训练来提升精准度,文档地址;这个不作为这次讨论的重点,本篇文章着重解决的场景是一段长语音识别文本如何获取想要的关键词,比如“等下一个班车”,那么解析的关键字可以是“等下,一个,班车”,但实际我们可能想要的是“等,下一个,班车”。
切词我们用到的是Python的一个好用的中文分词第三方库,因为是第三方所以需要我们自己先安装一下:
如果你用的是Python3 则需要执行:(如果不清楚当前Python版本可以执行python -V查看)
安装好后,我们先看一下效果,继续拿“等下一个班车”做实验:
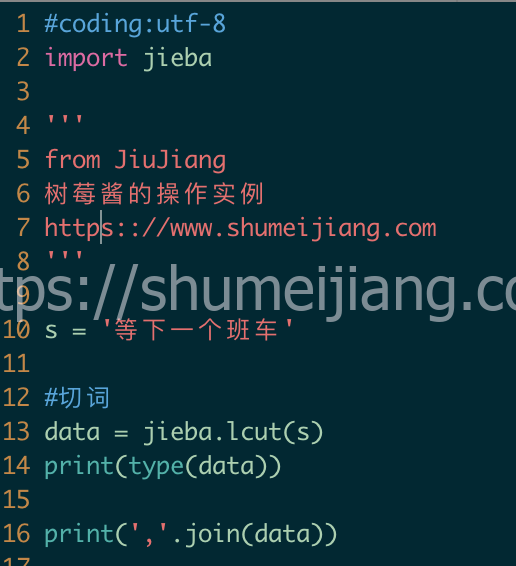 切词示例
切词示例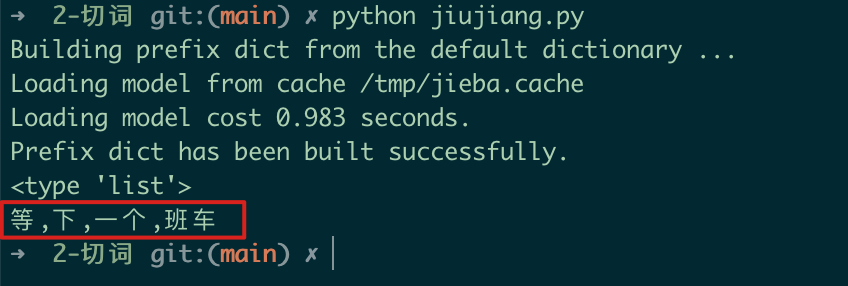 执行效果
执行效果 第一张图是切词的代码,可以看到我们输入的文本是“等下一个班车”,我们预期的是“下一个”;第二张图是返回的切词结果,原本返回的是list结构,为了直观我们修改为了逗号分隔的字符串,从字符串可见,“下一个”被切分的太细了,成了两个词“下”和“一个”;这个对于后续的判断可能会出现误导;倒不是说切词不对,只是没有符合我们的预期而已;
为了解决上面的问题,jieba还提供了另一个方法,可以通过我们自定义需要的词来切分;还是以上面的例子为例;
 示例
示例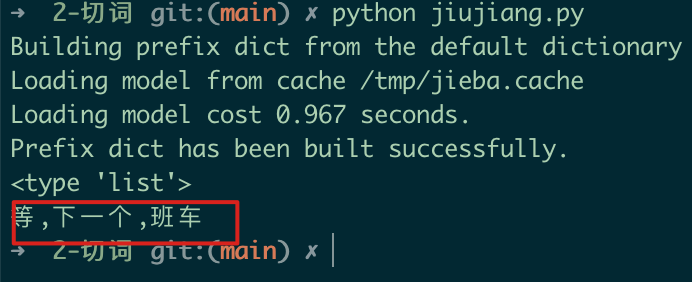 新的切分结果
新的切分结果 从上面的新的切分结果来看,已经能达到我们预期的结果,当然add_word这个函数可以多次添加同时执行,以满足我们同时需要切分多个词的需求。
下面的表格是jieba模块常用函数的讲解:
| 函数 | 含义 |
| jieba.cut(s) | 精确模式,返回一个迭代器,可遍历获取 |
| jieba.cut(s, cut_all=True) | 全模式,把可能的词都切出来 |
| jieba.cut_for_search(s) | 搜索引擎模式,切分对搜索引擎友好的词 |
| jieba.lcut(s) | 精确模式,返回list类型 |
| jieba.lcut(s, cut_all=True) | 全模式,返回list类型 |
| jieba.lcut_for_search(s) | 搜索引擎模式,返回list类型 |
| jieba.add_word(w) | 添加自定义切分词w |